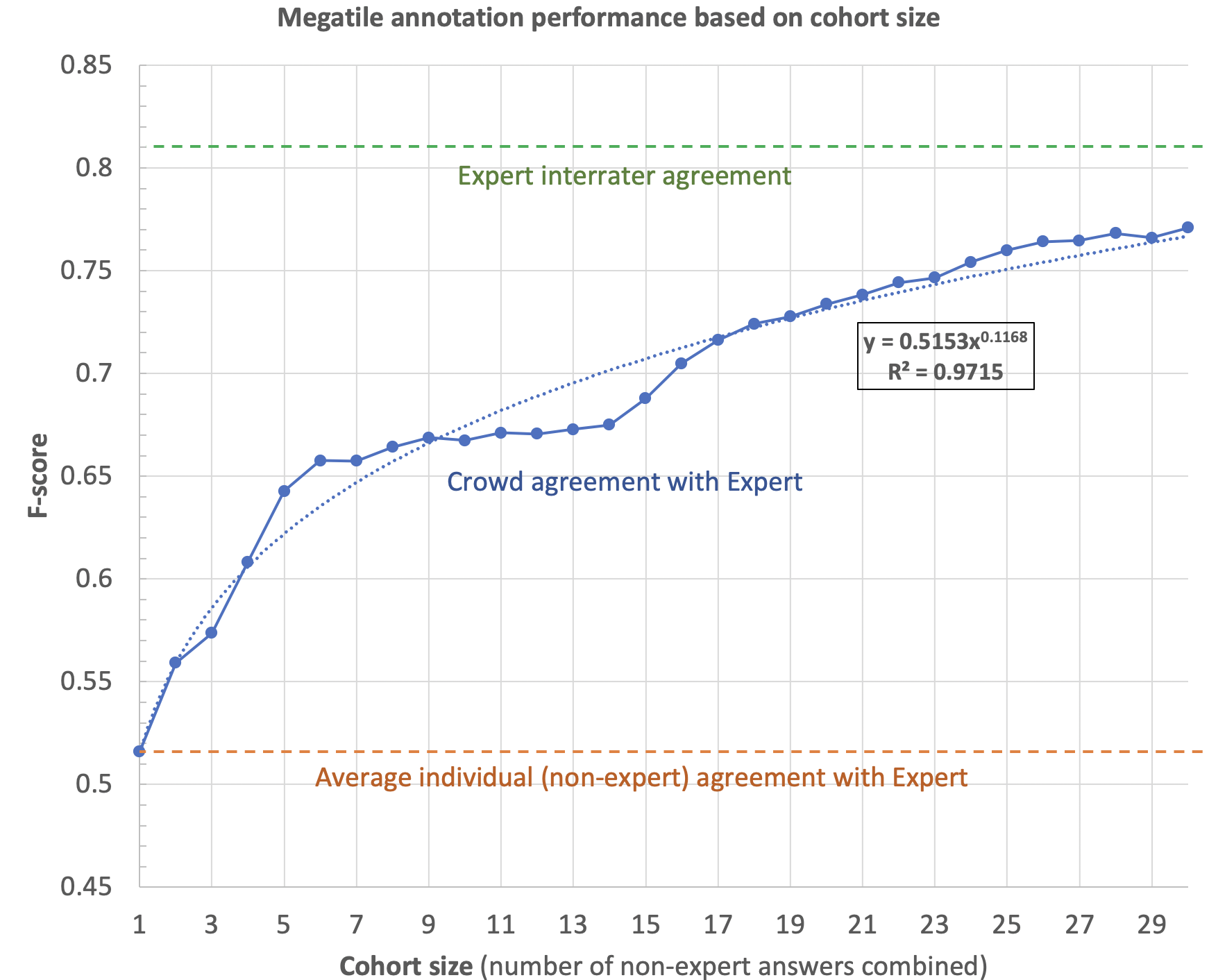
This full–day hackathon provides pilot data for developing novel hybrid intelligence methods to enable the rapid, high quality analysis of high volume biomedical imagery. We recently collected pilot data from a prototype crowdsourcing platform demonstrating that individual non–expert annotators achieved an average F–score of 0.49 relative to expert pathologists who exhibited interrater agreement of 0.81.
Our impact goal for this workshop is to accelerate Alzheimer’s disease research investigating disparities in disease prevalence between Hispanics and non–Hispanic whites. Our hackathon goal is to produce hybrid intelligence (HI) algorithms that generate expert–like crowd answers by sensibly combining annotations from multiple non–expert contributors. We will encourage synergies in the coevolution of human and machine–based agents while considering power dynamics and potential inequalities.
Workshop participants will be provided with a full research context, an explanation of the pilot data and analytic goals. Participants will self–organize into groups and hack their approaches, submitting ideas, designs, as well as algorithms to receive test feedback, making revisions as time permits. Groups will present their approaches and results. A prize will be awarded to the most accurate hybrid intelligence predictor, and participants will be invited to be involved in implementing their methods in the actual public–facing platform used to analyze the biomedical data (following external validation). We will seek to publish all HI methods and results from the workshop in a suitable open access journal.
TOPICS AND ISSUES
We seek to develop novel hybrid intelligence methods to enable the rapid analysis of high volume biomedical imagery to accelerate Alzheimer’s disease research investigating disparities in disease prevalence between Hispanics and non–Hispanic whites. Epidemiological data suggest Hispanics are at a higher risk of developing Alzheimer’s disease (AD) and have a higher occurrence of cerebrovascular disease (CVD) when compared to non–Hispanic Whites (NHWs). We are collaborating with researchers at the University of California to examine the neuropathologic landscape of AD across Hispanic and non–Hispanic white (NHW) decedents.
To this end, we use a diverse cohort to examine a spectrum of genetic, clinical, and demographic variables in order to improve our understanding of the complex and multiple determinants in dementia outcomes between these groups. In this context, we have used purely computational approaches based on a type of machine learning, convolutional neural networks (CNNs). CNNs have produced quantitative scores for whole slide images providing a proof of concept for scalable deeper phenotyping of neuropathologies.
However, these works so far have utilized highly trained experts to provide neuropathological classification labels, which can then be used to help train a CNN to automate the classification. While our initial application of this approach looks promising, we have observed data–related limitations in the performance of the predictive model stemming from both a paucity of training data and inter–rater disagreement. Moreover, we relied on imagery acquired from a single source. Achieving sufficient generality will require a much higher volume of multi–source data. The key issue is that it would be time–prohibitive to acquire the needed volume of high–quality, multi–source, expert–labelled data needed to train a CNN to meet our stringent data quality thresholds if we must rely on a handful of expert labelers.
To address the need for higher analytic throughput, we seek to launch a citizen science project and grow a thriving and self–sustaining community of volunteer participants, who contribute to accelerating our data analysis while receiving the benefits of community support, patient empowerment, and learning about dementia research. This endeavor is expected to scale our analytic capabilities in support of more rapidly understanding the neuropathologic landscape of Hispanics compared to NHWs and determine if this landscape is altered by clinical, genetic, and demographic variables.
Previously, we have successfully developed and deployed a citizen science platform that has already collected 2.5 million crowd– generated annotations from over 50,000 public volunteers. Further, we have achieved data quality exceeding laboratory–based analysis of experts by implementing specialized aggregation methods combining labels from different public volunteers into a single “crowd answer” that reliably exceeds expert–level classification performance in biomedical annotation. We seek to leverage these competencies and methods toward developing a new citizen science platform geared to the needs and sensibilities of the Hispanic community, so we may recruit those of this underserved population to provide crowd-based annotations as this would also serve as an outreach and educational component to support a fully automated and highly accurate analytic pipeline for quantifying neuropathology in AD.
PRIOR RELATED WORK
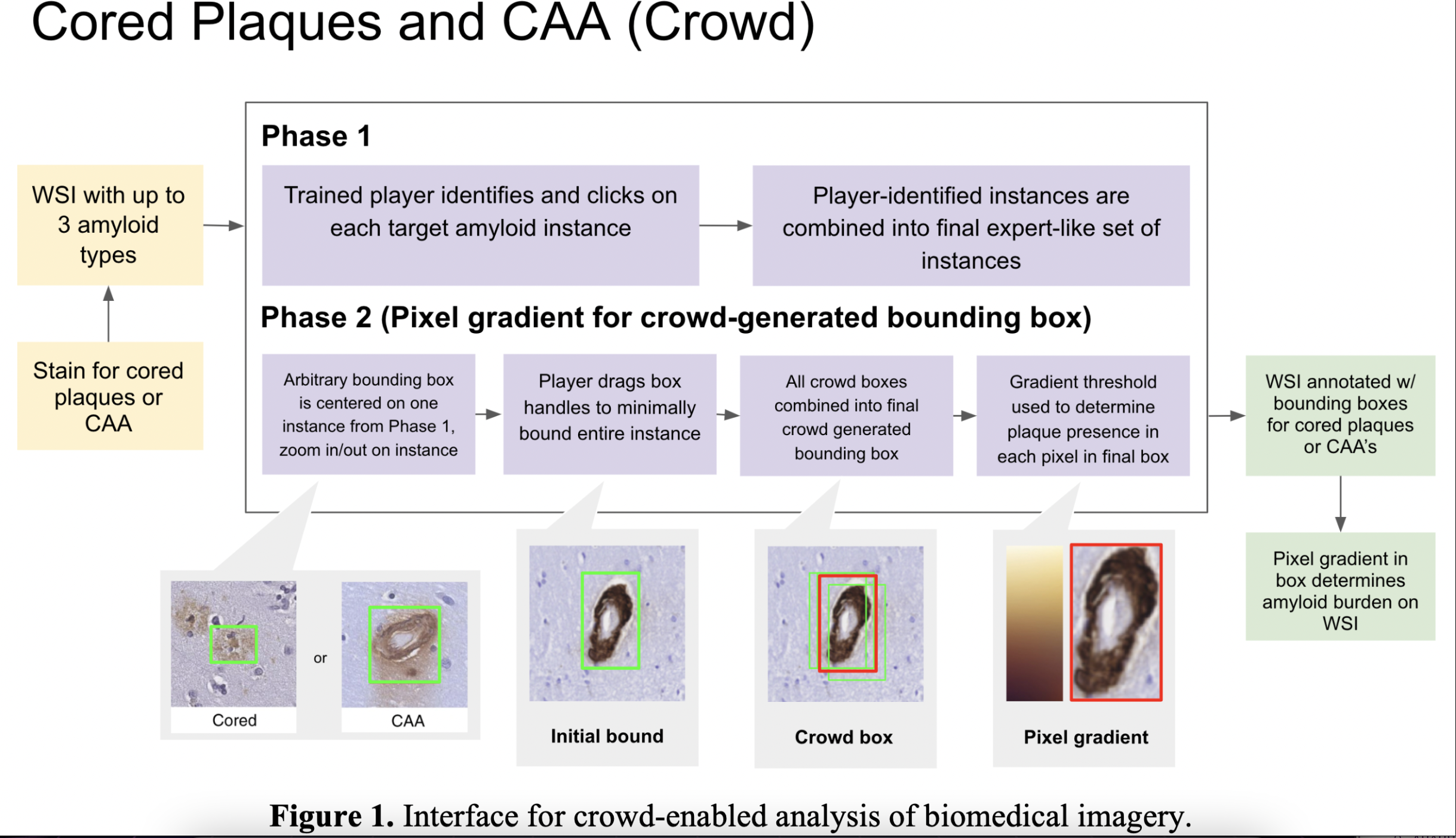
In recent work, supported by the U.S. National Institutes of Health (NIH), we have developed online interfaces (Figure 1) to engage public volunteers in the analysis of whole slide images of brain tissue to identify occurrences of toxic amyloid plaques and quantify the associated burden. Using these interfaces we conducted a pilot study, in which we invited 30 members of the general public to analyze 80 biomedical images, and compared their results to interrater agreement among trained pathologists (experts). On average, untrained individuals achieved an F-score of 0.49 compared to interrater agreement of 0.81.
Our goal with this hackathon is to develop novel wisdom of crowd methods to improve on this result by developing new approaches for algorithmically combining answers from several volunteers into expert-like crowd answers that meet or exceed interrater agreement.
We also seek to address the responsible inclusion of humans in hybrid intelligence systems during this early stage of development to ensure that these considerations are integral to potential solutions. This includes reflections of fair involvement of participants or power dynamics and potential inequalities that may arise.
Finally, we aim to explore different interface designs for this new citizen science project that allow participants to solve the task in an intuitive, interesting, and entertaining way. Thus, we invite workshop attendees to contribute to one or more of the different tracks:
Algorithms
Interfaces
Human involvement
Wild track
While hackathon participants can choose which track to focus on, we encourage everybody to consider questions of the third track in all approaches. Workshop attendees do not necessarily require a coding background to contribute to the hackathon, and indeed it would be interesting to have mixed groups.
References
[1]Michelucci, P., Onac, L., Couch, J., Sherson, J., Rafner, J., Bekins, S.H., Solovyev, R., Brodt, K., 2022. Exploring CrowdBots: a new evolutionarypathway for citizen science projects, in: Proceedings of Engaging Citizen Science Conference 2022 —PoS(CitSci2022). Presented at the Engaging Citizen Science Conference 2022, Sissa Medialab, Aarhus University, Denmark, p. 122. https://doi.org/10.22323/1.418.0122
[4]Rafner, J., Gajdacz, M., Kragh, G., Hjorth, A., Gander, A., Palfi, B., Berditchevskiaia, A., Grey, F., Gal, K., Segal, A., Wamsley, M., Miller, J., Dellermann, D., Haklay, M., Michelucci, P., Sherson, J., 2022. Mapping Citizen Science through the Lens of Human-Centered AI. Human Computation 9, 66–95. https://doi.org/10.15346/hc.v9i1.133
[5]Vepřek, L.H., Seymour, P., Michelucci, P., 2020. Human computation requires and enables a new approach to ethical review. https://doi.org/10.48550/arXiv.2011.10754